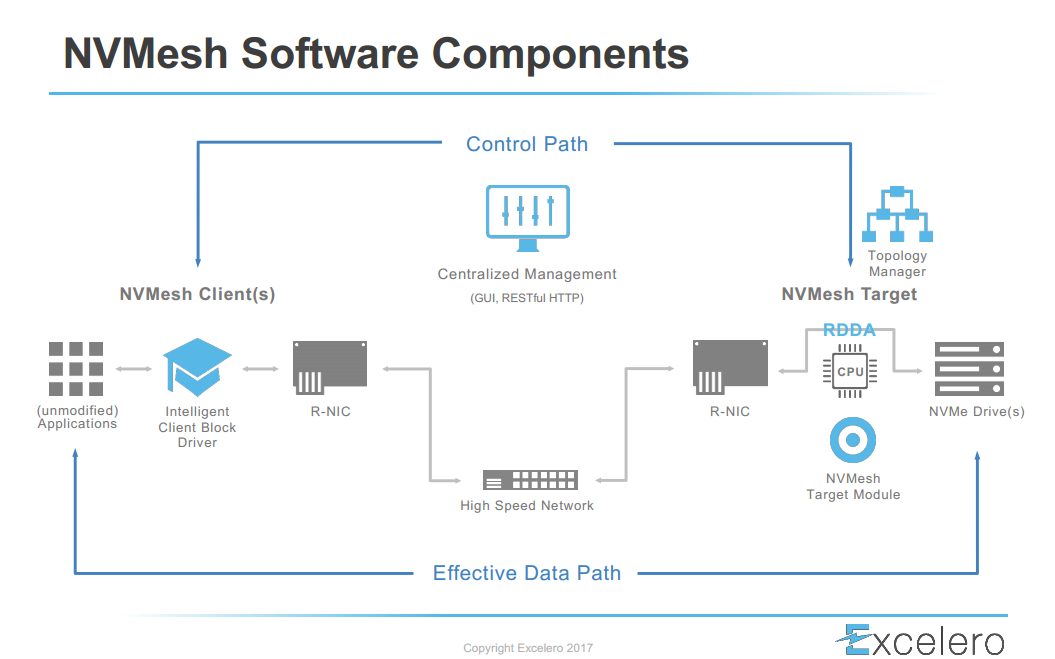
Excelero’s NVMesh is a distributed, software-based data storage system. What is unique about NVMesh is that the architecture is 100% converged: the data-path runs exclusively on the client side, involving no CPU cycles on the server side. This is particularly interesting for hyperscale applications as there is no noisy neighbors effect. An important component in the NVMesh architecture is the TOpology MAnager (TOMA), an intelligent cluster management component that provides volume control plane functionality and enables data services such as RAID, erasure coding and data sharing (among client machines). In this article, we dig a bit deeper into some of the different roles of TOMA.
Data Integrity
NVMesh was designed to deliver extreme performance. When creating data services, we try to avoid serialization of operations as much as possible: clients typically write to all the copies of a mirror in parallel. The same applies to locks, which are essential for data integrity purposes. Without locks, clients could override each other’s work when writing to different mirrors and cause data to be out of sync, which would be a catastrophic data integrity issue. TOMA governs block storage client connectivity to storage devices and to lock mechanisms to ensure that multiple clients access distributed volumes in a consistent manner.
Data Availability
TOMA also tracks the liveliness of drives and of other storage target modules to enable seamless volume activity upon element failure. Upon recognizing a failure, the topology manager performs the actions required to ensure data availability and consistency. It also manages and engages in invoking recovery operations upon element resumption or introduction of a replacement element.
TOMA is the orchestrator for recovery operations while other elements will perform the actual processing. As TOMAs work in concert, the orchestration itself can handle multiple failures requiring reinitiating recovery operations, as needed. One thing that the developers find time and again is that everything that can go wrong, will do so at some point. The system, as a whole, needs to be as resilient and resourceful as possible in avoiding service disruptions.
Synchronizing Topology & Clients
TOMA is deployed in a distributed fashion: TOMA instances (TOMAs) run on each server of the NVMesh cluster. TOMAs perform another two key roles, synchronizing the topology between themselves and synchronizing the clients. Topology is the actual state of all components involved in the NVMesh system that can affect how I/O is executed. TOMAs synchronize this topology and the control logic between the instances themselves. TOMAs also synchronize their clients to avoid data corruption. We aim to run all synchronization tasks without pausing the I/O, leveraging some pretty unique technology. This translates into minimal loss of service accessibility and improves I/O determinism.
Here are some interesting potential scenarios that TOMAs handle:
- Any number of servers might crash simultaneously.
- NICs and network switches might malfunction, resulting in partial or non-symmetrical disconnects between TOMA instances or between TOMA instances and their clients.
- Clients might crash or lose their network connectivity in the middle of a multi-node I/O operation.
- Volumes are created, deleted, and modified on the fly.
- Disks and NICs are hot-plugged, and hot-unplugged, potentially on a different server.
In any of these scenarios, the states of the servers are temporarily or permanently not aligned with each other and the TOMAs must synchronize all storage consumers in a consistent manner. TOMA does all this synchronization without relying on clock consistency. The time on each server’s clock could be completely different time, or even be erratic, making time jumps, and this will have no effect on the correctness of the TOMA state transitions.
The fact that the servers are unaware of the client’s I/O implies that the server side of the logic cannot redirect or block specific transactions. This implies that TOMA can only use control commands to instruct the clients about the new topology. Naturally, this complicates things when a RAID-1 mirror is going down or coming up, primarily since there is no way to guarantee that all the clients get the instructions simultaneously. This is where unique technology imported from a different field of computer science helps us.
Example: It is valid for one client to write only to the one mirror of a RAID-1 and another client to write to both mirrors, as long as they both read data consistently. Eventually, both clients will switch to the latest topology where they both work in the same way. The ability to operate with eventual consistency of the topology without compromising on data integrity is hard, but valuable for the end-user.
Determining the right order of operations to overcome failure and to maintain I/O service and to restore normal operation after the failure state has gone away is a logically complex process. Doing it in a distributed scalable way is an even bigger challenge, but that is what TOMA is all about.
The TOMA is designed to run in massive clusters of servers, each connected to many clients. It enables separation of the control and data planes and plays a crucial role to enable enterprise data services. Therefore, our QA teams spend a lot of time testing TOMA. We have built extensive test environments to stress test TOMA under all kinds of failure conditions: network failures, keep-alive timeouts, split brain scenarios, faulty drives, faulty NICs, etc.




