
NVIDIA GPU systems have become the go-to resource behind AI and ML workloads, with NVIDIA DGX-1 and DGX-2 systems practically synonymous with GPU computing. Likewise many data center administrators prefer the performance density achieved by adding local SSDs to their compute servers. However the storage and networking solutions to support GPU-accelerated architectures have yet to solve a central issue: efficient I/O with such enormous data volumes.
 NVIDIA’s latest innovation is NVIDIA Magnum IO, a suite of software for dramatically greater data throughput on multi-server, multi-GPU computing nodes than previously possible. A key feature of NVIDIA Magnum IO is NVIDIA GPUDirect Storage, a technology that provides a direct data path between GPU memory and storage, enabling data to bypass CPUs and travel on “open highways” offered by GPUs, storage and networking devices.
NVIDIA’s latest innovation is NVIDIA Magnum IO, a suite of software for dramatically greater data throughput on multi-server, multi-GPU computing nodes than previously possible. A key feature of NVIDIA Magnum IO is NVIDIA GPUDirect Storage, a technology that provides a direct data path between GPU memory and storage, enabling data to bypass CPUs and travel on “open highways” offered by GPUs, storage and networking devices.
With NVMesh® software-defined block storage, Excelero is among a select set of industry leaders who have adopted the NVIDIA-FS Driver API and other tools such as CUDA APIs to seamlessly integrate their solutions into the GPUDirect Storage framework. NVMesh incorporates similar principles as NVIDIA Magnum IO – bypassing CPUs to directly access NVMe media. By combining GPUDirect Storage with NVMesh, users bypass CPUs all the way from GPU memory to NVMe devices – achieving frictionless access to NVMe’s superior performance for shared NVMe storage at local speed. Excelero holds several US patents governing techniques for this bypass and has several more related to it that are pending patent approval.
Excelero NVMesh solves the “storage bottleneck” that AI and ML users report that they often experience through two architectural innovations:
- The storage services in NVMesh are implemented as client-side services, with target side CPU bypassed completely for data path. Getting rid of any centralized entity on the data path for metadata or lock management means that the clients are totally independent and there is no inter-client communication. This allows NVMesh to gain access to the full performance of NVMe media at any scale – starting from a few drives in a server to massive scale of hundreds and thousands of storage nodes. With this architecture NVMesh supports heterogeneous deployments and is ready to embrace new and faster emerging media types including Storage Class Memory devices.
- Flexible data protection schemes provide the improved ROI which is extremely valuable in the AI/ML market targeted by NVIDIA Magnum IO since the amount of data generated and used to train the models grows exponentially. MeshProtect is NVMesh’s flexible data protection technology, providing multiple redundancy schemes that can be tuned for specific use cases and data center restrictions and requirements to ensure reliability and reduce cost.
Elastic NVMe for GPUs
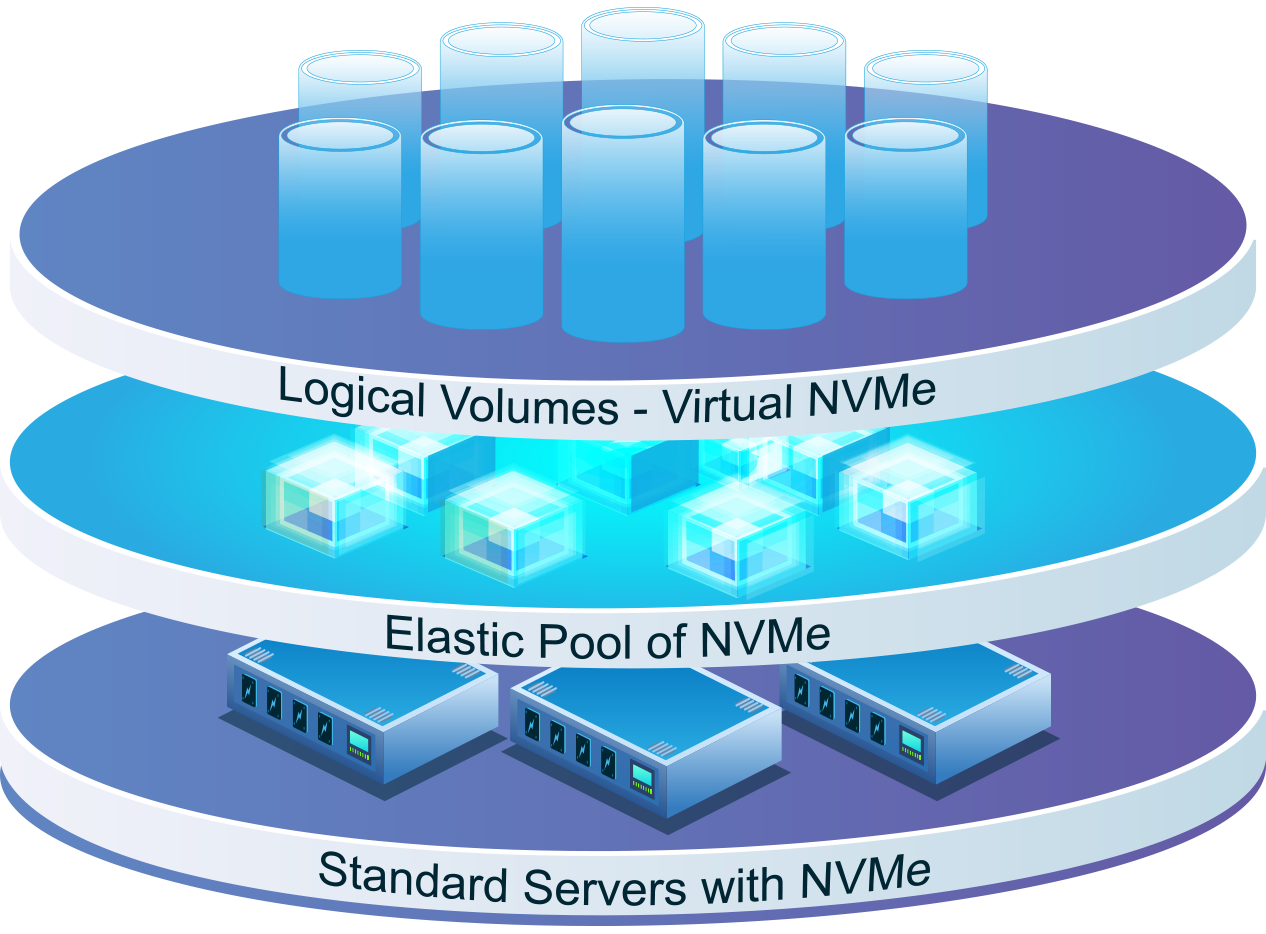
In NVMesh, drives are perceived as resources that are pooled into a large storage area. Logical volumes are then carved out of the storage area and presented to clients as block devices. Volumes may span multiple physical drives and target hosts, but do not need to use entire drives, so a single drive can be allocated to multiple volumes.
In addition to extremely high performance options of striped and mirrored volumes, NVMesh supports MeshProtect 60 which provides volumes protected by distributed Erasure Coding. This option provides N+2 redundancy level with only 20% storage capacity overhead. The uniqueness of MeshProtect is that this option provides read performance on par with the striped and mirrored options while requiring minimal write performance trade offs for the type of workflows mostly used in AI/ML scenarios.
All of the MeshProtect schemes can be used to run local, parallel or distributed file system of choice making the deployment of these new technologies seamless and frictionless.
We applaud NVIDIA for extending the GPU acceleration that has revolutionized computing all the way through to IO and storage with NVIDIA Magnum IO and GPUDirect Storage.
For more on how Excelero’s NVMesh architecture works, and its impressive results in real-world AI and ML deployments, visit https://www.excelero.com/use-cases-ai-ml/.
STFC Case StudySTFC Case Study



