
What COVID-19 Taught a Tier-1 Web Firm
With COVID-19 the efficiency of remote work became a high priority task for many organizations. Along with it came the challenges of making sure that continuous integration and delivery (CI/CD) deployments perform at the highest levels.
The experience of a Tier 1 web firm in satisfying seemingly incompatible requirements of making all elements of the CI/CD infrastructure scalable, performant and container-native is particularly instructive, as a wide range of organizations rethink development processes post-pandemic.
Prior to a remote work environment, developers at this Tier 1 firm used physical servers with fast local NVMe flash to run their routine CI/CD tasks such as compilation, building and local testing. As the development organization moved to working remotely, the initial plan was to allocate dedicated physical resources for each developer to prevent them from wasting precious developer time. However, it quickly became clear that this scheme made resource usage extremely inefficient, as systems idled for long periods of time.
The solution was to create a large and scalable pool of servers from which developers can allocate virtual resources for a specific task. At a scale of tens of thousands of servers, a mature control environment at this organization becomes mandatory. Kubernetes is the natural choice allowing not only a tried-and-tested environment, but also a way to leverage public cloud resources as a bursting option or even in a hybrid deployment mode.
One Critical Focus
The main requirements facilitating a move to Kubernetes were defined as follows:
- Performance – Provide sufficient performance so that the developer’s experience is comparable with the bare-metal server experience from the pre-COVID era.
- Scalability – The solution should be able to grow to thousands of servers per cluster to meet expected peak demand.
- Fault tolerance and high availability at scale – The system should be effective in handling compute, networking and storage failures.
- Maintainability – It should be possible to upgrade the system without taking the cluster down and while providing 24×7 service.
A key to overall performance is the storage aspect of this project. Organizations can either become mired in typical challenges, or leverage innovations that deliver far greater efficiency for an impressive competitive edge.
Kubernetes deployments typically raised the question of container-ready vs container-native storage. Both are consumed using the Container Storage Interface (CSI), but the latter is deployed and controlled via Kubernetes and does not require any external entities. When bare-metal like storage performance is of the utmost importance and it often is required to satisfy the overall user experience requirement, then it is a common misconception that container-native storage (CNS) solutions are not up to task.
Avoiding Data Path Issues in CNS
The organization leveraged a container-native software-defined storage solution (Excelero NVMesh®) for low-latency distributed block storage for web-scale applications. It enables shared NVMe across any network with support for any local or distributed file system. Intended for larger data centers with upwards of 100,000 nodes, the system avoids any centralized capability for the data path, enabling a direct application of NVMe to the data path. (Figure 1). Clients are completely independent with no-cross client communication ever required. Its intelligent clients also communicate directly with targets. This reduces the number of network hops and the number of communication lines, making the pattern acceptable for a large-scale environment, where the number of connections is a small multiple of the domain size.

Figure 1. Excelero NVMesh components
Privileged Containers for High-Performance
When running under Kubernetes the approach enables high-performance in the CNS realm. This is achieved by controlling deployments of the client and target device drivers with privileged containers, thus leaving the data path unaffected by the containerized nature of the Kubernetes environment and moving all the control and management plane components to native container API-based operations. The resulting deployment looks like the following diagram. (Figure 2). It is container-native while preserving the performance characteristics of bare-metal storage software.
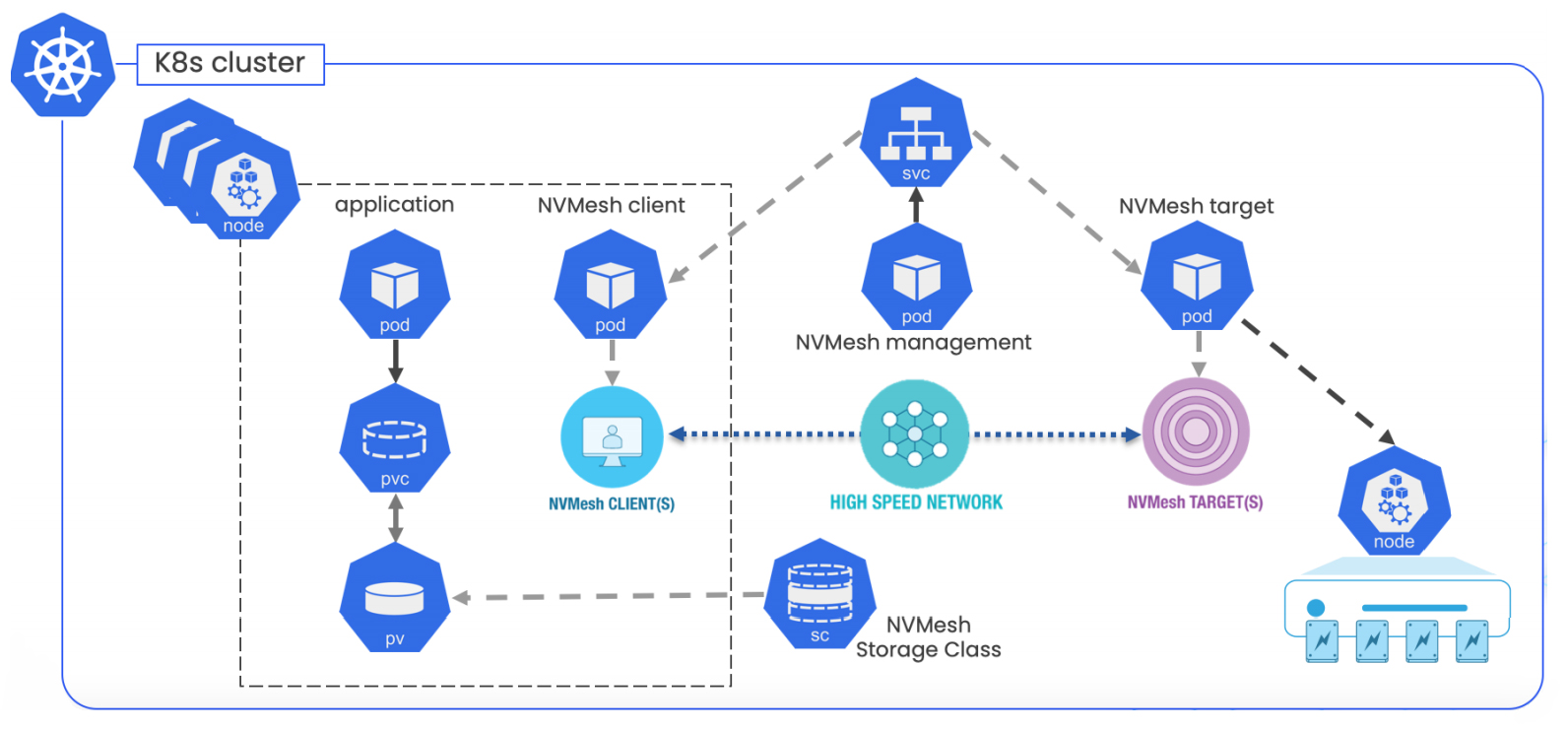
Figure 2. NVMesh as a container-native storage software solution
In the Tier-1 web firm’s production environment, application-level performance is 15%-20% higher than in the bare-metal case, as the storage software aggregates several remote NVMe drives in a virtual volume presented to user containers running applications. The next challenge was to provide the highest level of availability and fault tolerance for such a critical part of operations. The inherent logical disaggregation of storage from compute enables moving client workloads between compute nodes in case of an application server failure. An understandable follow-on question is how the architecture would handle rolling security or scheduled upgrades to the storage nodes, or prevent downtime when rare edge cases or storage cluster issues occur. To mitigate this, the organization decided to use a cloud-like deployment model depicted in the following diagram. (Figure 3).
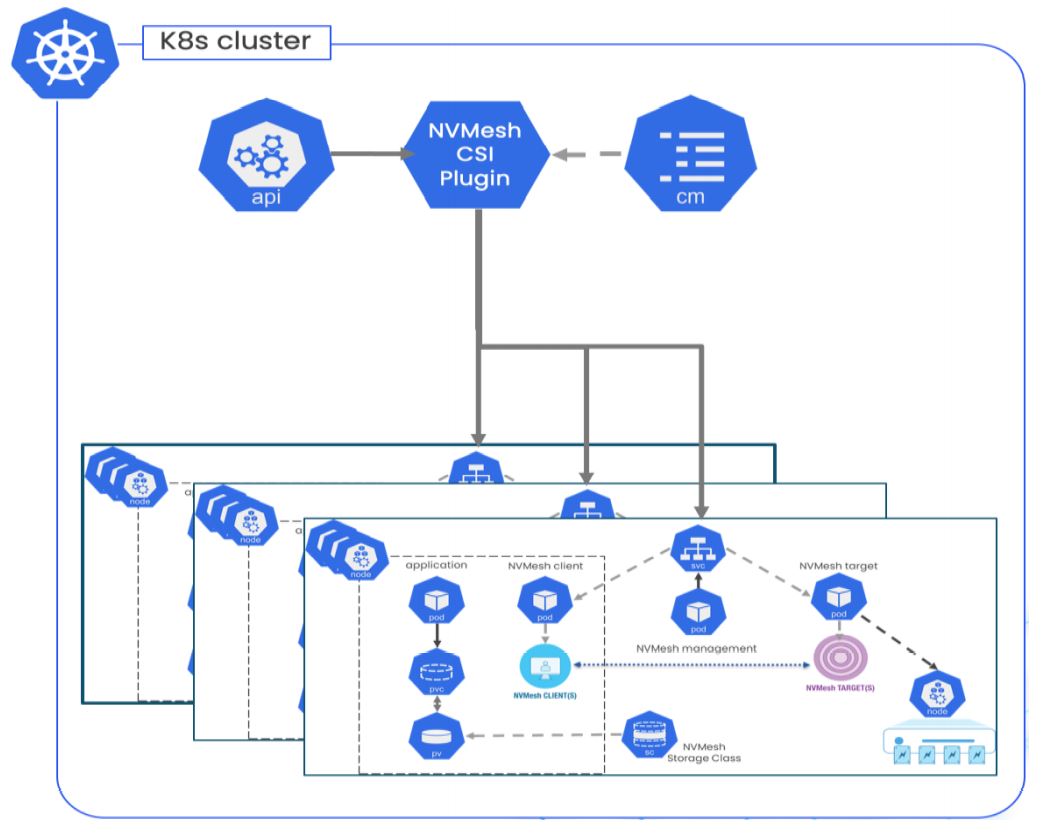
Figure 3. Cloud-like deployment model using Kubernetes clusters
This design follows the principles very neatly outlined in an AWS paper on fault isolation:
https://docs.aws.amazon.com/wellarchitected/latest/reliability-pillar/use-fault-isolation-to-protect-your-workload.html. The large Kubernetes cluster serves as a “local zone”. An availability zone
may have several such local zones. Each sub-cluster is a cell within such a local zone. Several logically independent cells within the same Kubernetes cluster provide the following benefits:
- They limit the scale of storage networking, allowing for lower latencies.
- The “blast radius” of storage-related issues is limited, just in case.
- The ability to independently upgrade storage clusters without any solution downtime and
without the performance slowdown that too frequently accompanies rolling updates.
The CSI architecture has an inherent limitation with a singleton per Kubernetes cluster. The deployment team used Kubernetes ConfigMap capability to overcome this. This allows coordination of the deployment of user pods, along with allocation of the corresponding Persistent Volumes in the storage sub-clusters.
Putting it to the test
The preparation for the production roll-out was done over the course of a few months to get everything perfect using a few small clusters. Then, the system went live with local zones of 650 compute nodes each. Each local zone has 16 cells and each cell has 4 storage nodes. As the service became widely popular, beyond expectation, the next set of 16 zones were deployed in just one week. The use of generic hardware meant it was “just” a matter of software deployment at scale.
Total cost of ownership
While the organization did not complete a formal total cost of ownership (TCO) analysis for the CI/CD storage system, following is an example back-of-the-envelope calculation one could do for a similar environment with the same challenges. A typical developer in the enterprise uses a piece of private infrastructure on average 10% of the time. The enterprise has developers around the world. With shared infrastructure at 50% utilization on average this means a 5x reduction in cost. Reducing run-times by 20% gives another efficiency saving on top. Finally, one also gains the flexibility to upgrade and maintain broken systems without penalizing users in contrast to the situation with infrastructure allocated on a per-developer basis.
Summary
Large-scale efficient deployment of a shared infrastructure is a persistent issue, from the feedback those who run a data center. The paybacks in terms of total cost of ownership can be astounding. Kubernetes is a great tool for managing applications and application life cycles with ease for such environments. If done properly, Kubernetes handles a lot of scheduling complexity and can provide a scalable, even elastic, and fault tolerant environment. However, users will rightfully complain if their experience is hurt. Slowness leading to humans waiting is counter-productive. Steady performance is key, and storage is a critical component for this steady performance.
Container-native storage systems can remove storage performance concerns with an adroit handling of data path issues – and without adding complexity for devops leaders who are familiar with Kubernetes. Deeply ingrained fault tolerance, through support for a cell-like zoning architecture, also supports critical system fault tolerance and maintainability at scale.
The experience of this web firm shows that enterprises enduring low efficiency or employing complex solutions in CI/CD systems should consider moving to Kubernetes as a way to simplify efficient scaling by taking storage issues out of the equation.
Author’s Bio
Kirill Shoikhet is CTO of Excelero Storage, providing software-defined storage for IO intensive workloads, including its flagship NVMesh® solution for running natively in Kubernetes. He holds 23 patents for foundational technologies in enterprise data center management.
As a leading kubernetes storage provider, Excelero offers the performance of local flash with the persistence and scalability of centralized storage. Improve oracle database performance and achieve high throughput and low latency for mission-critical workloads with Excelero’s oracle cloud database solutions.




