
Converged storage – sometimes called hyperconverged infrastructure – is a concept that leverages standard servers to provide both compute power for applications and storage services from locally attached drives. For these configurations, it is highly desirable to minimize the use of CPU cycles for the storage services. Failing to do so leads to what is known as the noisy neighbor problem, which precludes deterministic application performance and may negatively affect the user experience. The “noisy neighbor” of storage activity causes problems for the applications that live nearby, on the same servers.
True convergence – without impacting the target CPU – is one of the biggest challenges in Software-defined Storage (SDS) architectures. In this article, we will try to explain why true convergence is so hard to achieve, and shine a light on how Excelero solves this problem.
Most storage solutions need to write and read data (Input/Output – IO) with the smallest possible latency and overhead to the CPU. Data IO requires two main operations: deterministic data locality and the actual IO transfer to/from that location.
IO Operations
In converged storage environments CPU resources need to be reserved for the applications, hence it is mandatory to minimize the CPU cycles required to share local drives. This is especially true when using fast flash drives, or SSDs, because their higher speeds normally consume even more of the CPU for I/O purposes. The immediate implication is that the actual IO operations must be completely offloaded from the CPU. One could use proprietary hardware to achieve this offload, such as Smart-NICs, FPGAs, or Smart-Disks, but this would massively increase costs.
To solve this problem, Excelero developed and patented the software-based Remote Direct Drive Access (RDDA) technology, using and mimicking remote direct memory access (RDMA) to allow clients to perform access to remote NVMe drives without executing any CPU instructions on the target side. This software does not require proprietary hardware, and can do magic with any RDMA NIC such as the Mellanox ConnectX-4 and ConnectX-5 network adapters.
Data Placement
Offloading the IO operations is important but it’s only one part of the equation. Equally important is the data locality (where is the actual block I want to write/read?). To determine locality, storage systems need to answer three “W” data placement questions, What, Where and When:
- The What question: What data needs to be read or written, is the easiest to answer as the answer is usually provided by the caller, the application.
- The Where question: Refers to where on the “logical volume” data needs to be written to or read from.
- The When question: Asks when the IO operation should be executed without exposing the logical volume to data corruption. This is especially difficult with mirrored, shared volumes and distributed file systems.
If the determination of the Where and When to place the data consumes significant CPU, you haven’t solved anything. But offloading data locality is a much more complicated task than offloading IO operations. Most storage solutions use a “centralized brain” to answer the Where and When questions. That centralized brain, running on some or all of the nodes, coordinates the answers to the remote clients’ Where and When questions by using synchronization and locking methods. This coordination typically takes a huge toll on the CPU and, as the number of clients increases, it increases the latency of the entire system. This is why most clustered systems hit a performance cliff at a certain scale.
There are two immediate conclusions from the above: IO offload without solving the data locality efficiency issue has limited merit, and using a centralized storage brain to provide the IO Where/When smarts takes considerable CPU resources, which contradicts the converged requirement to save CPU for the applications and limits scalability.
A New Approach to Creating True Convergence
The only way to provide a true converged environment is to offload IO and to drop the centralized storage brain, plus move data locality determination to the client. Client-side data locality means each client provides the answers to the IO coordination questions using only its own knowledge. The proposed solution uses CPU resources only to fulfil the client IO needs and it certainly scales, but this is not a trivial thing to build. The difficulty is that the nodes that hold the disks only provide a memory area for coordination and the synchronization operations are performed by the remote clients. Fortunately, the variety of synchronization operations that are remotely available is very small.
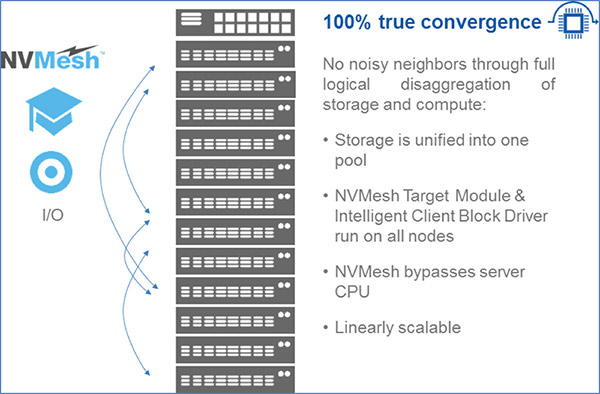
Figure 1: A true convergence solution enables distributed storage sharing without CPU overhead.
To date, achieving an efficient and scalable converged infrastructure with flash storage has been impossible. But by moving data locality determination to each client and using a new remote direct data placement method, this becomes possible. To learn how Excelero solved this and built a 100% true converged, 100% software storage solution, please visit https://www.excelero.com/product/nvmesh/
Ofer Oshri, Ph.D
VP R&D Excelero




