
The explosive growth in GPU computing for AI, machine learning and deep learning has rewritten storage requirements in today’s data center. Last month, Excelero was honored to host a webinar featuring experts from NVIDIA, Barclays and Excelero on accelerating deep learning with storage for GPU computing. A blog article revisiting the webinar and highlight the essentials was long overdue.
GPU storage is one of the most pressing challenges faced by AI/ML/DL deployments today. Traditional controller-based storage usually isn’t suitable, and each expert was a veteran of implementing from concept to production with these systems while navigating all manner of “gotcha’s” along the way. Given the highly informed questions from the large number of attendees, many of whom already have deployed multiple GPU servers, the challenge is a significant one.
The phenomenal advances in computing that the GPU offers, puts pressure to find the right storage that delivers at the right latency and throughput that GPUs need. Here’s three takeaways from the session.
Matching GPU and storage.
NVIDIA’s senior technical marketing engineer Jacci Cenci looked holistically at three data center challenges affecting data scientists:
1) the dramatically larger data sets no longer fit into system memory;
2) slow CPU processing;
3) complex installation and management.
As processing moves off the CPU toward GPUs, teams still find they need to adjust big data storage systems since the time for loading application data starts to become a strain on the entire application’s performance. She reviewed NVIDIA’s work with MAGNUM IO, whose accelerated compute, networking and storage approach can accelerate AI and predictive analytics workloads so users gain faster time to insights and iterate more often on models – key steps to creating more accurate predictions.
Practical deployment advice.
Dr. Dimitrios Emmanoulopoulos, lead data scientist, applied R&D and ventures CTO at Barclays, shared his personal perspective on fast storage and GPUs for AI, based on years of hands-on experience. His group handles numerous AI applications for a variety of business use cases, including fraud detection for credit card processing, recommendation engines, delinquency prediction, customer feedback classification, bond prediction, and other image and sound processing. Data parameters vary greatly across these use cases, with the only point of commonality being that they generate multi-petabytes of data. This type of data is usually stored in Hadoop as a data silo, which is superb for its original intention of creating libraries, but less optimal since the proliferation of frameworks sitting on top of Hadoop across an enterprise tends to create bottlenecks.
The current paradigm, Dr. Dimitrios explained, has profound cost and data center limitations, particularly when applications have to be distributed and multi-node. He detailed his team’s experience with Hadoop clusters, where GPU servers, a software-defined storage layer, and select open source software elements enabled a cost reduction of up to 90% – with 5x the compute power. Equally as importantly, the software-defined storage layer also enabled greater flexibility in adjusting storage to workload needs, and avoiding onerous proprietary hardware costs.
The latest in storage performance.
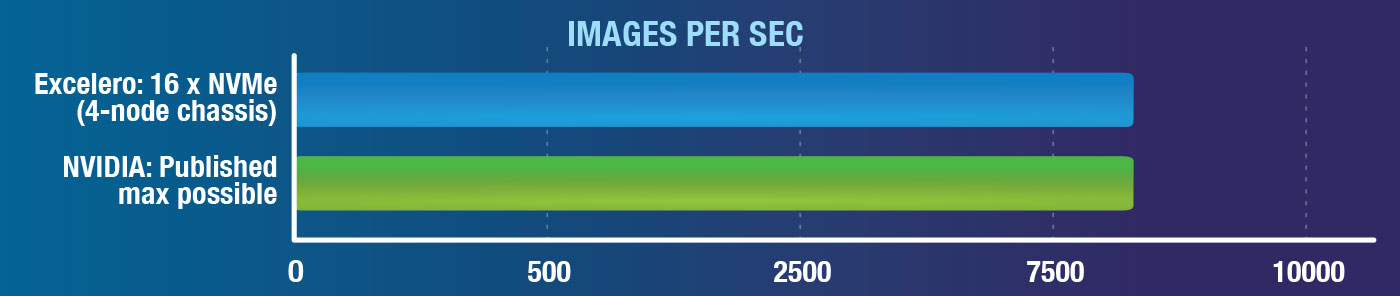
Excelero’s field CTO Sven Breuner shared new results of performance tests run on NVIDIA DGX servers and Supermicro BigTwins systems with NVMesh Elastic NVMe. Using the de facto standard ResNet test with TensorFlow and the ImageNet data set, Excelero sought to emulate the best and the worst case scenarios in AI/ML workloads. NVIDIA has published that maximum DGX image processing performance is 8000 images/second. Sven was proud to share that the tests demonstrate how a single NVMe storage appliance with Excelero NVMesh meets that maximum GPU utilization number as defined by NVIDIA. Given the highest published performance figure published online is <7000 images/second, achieved using 48 NVMe drives and 8 DGX servers, compared Excelero’s 16 NVMe drives and one DGX server running a local file system – the ResNet results that Sven shared clearly show NVMesh’s performance advantage.
Sven then shared additional tests showing an NVMesh XFS small file read performance with 4 Kb files on a single XFS filesystem that is shared across multiple DGX units. This addresses a common scenario in many AI/predictive analytics workloads where a massive numbers of small files still creates a GPU storage bottleneck. When running 4 NVMe drives on a 100GbEthernet network, Excelero’s NVMesh achieved over 1 million files/second performance with 4 Kb files.
The architectural advantage of NVMesh, he explained, derives in part from its use as an abstraction layer on top of individual NVMe drives, through which customers can create logical volumes – allowing the entire capacity of NVMe drives to be accessed enterprise wide, if customer so choose. Results affirm what IT leaders in the trenches know – software-defined scale out storage the only way to go to accelerate these highly demanding workloads.
Practical Questions.
Following the experts’ presentation, attendees asked questions about specifics that would enable optimal success:
- best methods to replicate/sync multiple geographic locations under different parameters
- in-memory technologies for CPUs, and why the massively parallel architecture of GPUs still exceed in-memory algorithms
- ways that NVMesh allows reads and writes from multiple DGX servers to the external NVMe storage
- using NVMesh most effectively both with a parallel file system, and without one
- and more.
Judging from the astute questions and the patience of attendees in staying well over the allotted webinar time to ask them, data center leaders know that effective storage for deep learning, machine learning and AI on GPU systems requires new thinking and approaches. Excelero is delighted to share its longstanding innovation in this domain – and is offering more webinars in the coming weeks. Stay tuned!




