
If you’re gonna bypass – then do it all the way!
The artificial intelligence, machine learning and deep learning (AI/ML/DL) domain is undergoing a profound transformation. A transformation that may not be evident at first glance, but like the iceberg, what’s beneath the surface requires that IT leaders chart a careful course.
There is a rapidly growing trend to develop modern data center architecture on a foundation that has been carefully built to use the CPU, GPU and DPU, where the CPU is responsible for heterogeneous compute tasks, the GPU for massive vector calculations, and the DPU for the data flow control. While DPUs are only starting to emerge, GPUs became an important part of modern data centers and are responsible for the surge of machine learning applications in recent years.
Since GPUs are able to process huge amounts of data, big data storage architectures need an efficient pipeline of data to GPU memory. Preloading the data to GPU memory only partially solves the problem. Passing the data through the CPU memory subsystem creates bottlenecks and inefficiencies that can lead to the underutilization of GPUs. Designs that provide an efficient and performant way to get data to GPU memory from storage enable optimal results. This understanding led NVIDIA to create the Magnum IO GPUDirect Storage initiative.
The much-heralded debut of NVIDIA GPUDirect Storage is a major milestone. We salute our colleagues for this elegantly simple approach to addressing bottlenecks that have forced AI/ML/DL and other IO-intensive workloads to require far costlier and less scalable storage.
Excelero’s view is that solving the GPU server side of the problem is only a partial solution. It dramatically reduces bandwidth as a workload chokepoint, mostly for large IO sizes. However, the latency challenge to storage performance remains. This is due to the fact that with traditional storage solutions the IO to GPUs path requires a lot of CPU cycles along the way meaning that:
a) Latency-critical workloads – e.g., small-to-medium image files or video fragments – are still delayed and do not allow full GPU utilization
b) Number of CPU cores serving storage need to scale with GPU capabilities, leading to an overall higher cost of the solution
Excelero’s approach with its patented Remote Direct Drive Access (RDDA) functionality within our NVMesh software-defined storage solution is to bypass the CPU on the storage server, providing a direct path between the application and remote NVMe drives. In dozens of deployments with supremely demanding workloads, the approach has enabled dramatically reduced latency and high throughput for IO intensive workloads.
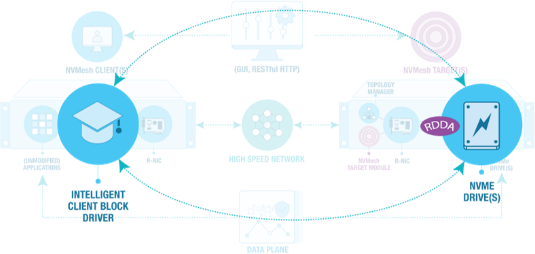
RDDA is similar to the NVMe-over-Fabrics protocol but with much lower latency and no CPU overhead. For example, in a write operation, the client sends the data, then the data lands in the host’s memory. At that point the RDMA NIC triggers an operation that tells the NVMe device to read data directly from memory and place it on the device.
Without RDDA, the NVMe device would send a notice to the CPU when this is completed – a task that consumes CPU cycles. Using RDDA, Excelero’s NVMesh reroutes the completion notice to the NIC, which will send the response all the way back to the client in one round-trip operation. This is the magic of RDDA, which enables extremely low latency. An entire round-trip operation adds about five microseconds of overhead over whatever the response time is of an NVMe device. This means if the system performs the write in 100 microseconds locally, an application writing through an NVMesh volume would require 105 microsecond response time.
When Magnum IO GPUDirect Storage and Excelero’s RDDA are combined, they provide a direct GPU-to-drive path for the most latency-sensitive applications. Like the iceberg, GPUDirect Storage is what you see above waters – yet the infrastructure beneath it is what often makes the difference to AI/ML/DL and other latency-sensitive workloads. Together with RDDA, the combination allows the data to flow efficiently from the NVMe drives, across the data center through fast RDMA networking, and out to GPUs – leaving CPUs to handle application stacks and configuration of the data path. The combination of Magnum IO GPUDirect Storage and Excelero’s RDDA also makes sizing of the solution easier, since one can separate CPU, GPU and storage sizing making under-utilization or over-compensation less likely.
Data center architects who harness the combination of CPU and GPU with an eye to assuring low-latency and high throughput with the most efficient modern infrastructure can gain an important competitive edge in infrastructure performance and cost-effectiveness. Innovators like Excelero are helping them to chart a new course around challenges seen and unseen in these innovative times.




